Data Client Library
Data Client Library - Slip din data fri
Demokratiser din data - det er et mantra vi har hørt længe. Hvis vi bare gav folket tilgang til vores data, så ville alt være vel i vores virksomhed. Alle beslutninger ville være datadrevne og BI support postkassen ville være tom.
Som så meget i IT verdenen, så er grundtanken god - det er enormt frustrerende for alle parter at skulle sende mails frem og tilbage mellem analytiker og BI/Datawarehouse for at kommer frem til det helt korrekte dataset, for derefter at starte forfra for at kunne inkludere faktor Z.
Standardsvaret har været “Self-Service BI” - et koncept der har udmyntet sig i mange facetter. Oplær alle i SQL, lav datamarter, lav kuber, pivot i Excel, PowerBI, Tableau og mange andre. Hver løsning kommer til kort på sin egen specielle måde.
Det er bestemt ikke blevet nemmere. Dataverdenen har bevæget sig mod noget der kan betegnes som en microservice tilgang til data. Data fra CRM systemet ligger i Kafka, kundebasen findes i en Parquet fil i datalaken, men salget ligger i en database, hvorefter det skal beriges med et API kald til en tredjepartsdataleverandør.
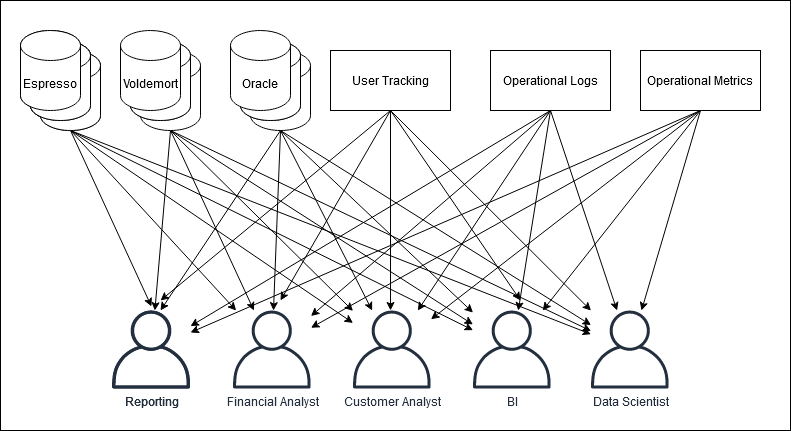 Inspireret af Linkedin’s data pipeline circa 2011 kilde
Inspireret af Linkedin’s data pipeline circa 2011 kilde
Everything-as-code#
Everything-as-code er det vi sigter imod - når alt er defineret i kode, kan man versionskontrollere, genskabe og flytte sine data nemt. På analysefronten ser vi en tilsvarende migration fra Excel til programmeringsprog som Python og R for at kunne analysere større mængder data på en mere reproducebar måde.
De sidste par år har vist at det er svært at lave reproducerbare og testbare analyser i Excel. Viktige økonomiske analyser der viste sig at være forkert fordi forfatterne glemte at trække formelen hele vejen ned. DNA sekvenser er blevet omdøbt , fordi Excel automatisk formatterede dem som datoer.
Strategiske beslutninger skal træffes på analytikerens resultater (hvis det ikke er tilfældet, hvorfor overhodet lave analysen?) - hvis det resultat er forkert fordi analytikeren glemte at where clause nr 15 skal inkluderes hvis man inkluderer produkt A, så har det potentielt store konsekvenser for din virksomhed.
Dette er en glimrende anledning til at introducere et Data Client Library
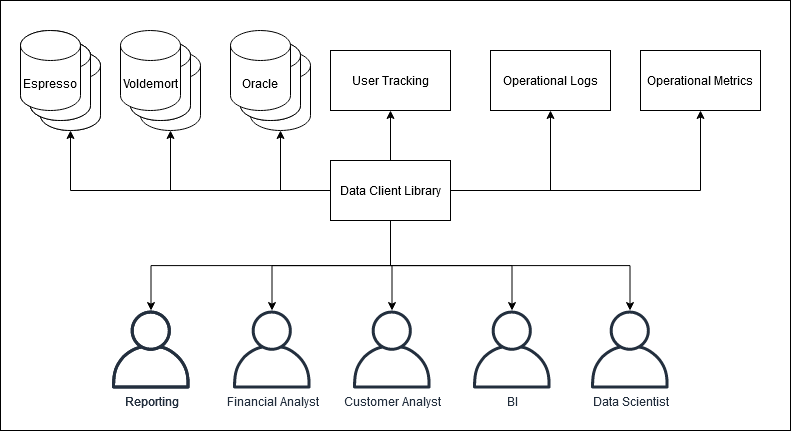
Data Client Library - Data access for everything-as-code#
Analyse befinder sig i en ny verden af kode. Hvis jeg vil analysere tweets på Twitter, så kunne jeg gå ind på twitter.com og kopiere tweetsene ind i en tekstfil. Eller jeg kan installere et Twitter client library, hente data og lave beregningerne direkte i Python. Jeg behøver ikke vide noget om hvordan Twitter fungerer bagved - jeg specificere kun at jeg vil have alle tweets fra @MetroenKBH fra sidst uge, og voila.
Et Data Client Library følger det samme princip. For at lave gode analyser, så er det ikke viktigt at en analytiker ved hvor data opbevares eller præcis hvordan man har valgt at definere hvad en ny kunde er. En analytiker bør bruge et Data Client Library og kalde en funktion der henter alle nye kunder mellem dato A og B, og specificere at de skal have købt produkt C.
Hvordan Data Client Librariet kommer frem til det svar er ligegyldigt. Måske skal den kombinere data fra to databaser og kalde en API. Måske indebærer det en SQL der involverer 10 joins og 20 where clauses. Vi kan bede analytikeren om at huske det - eller vi kan definere det i kode.
Transparens og Dokumentation#

Photo by Yancy Min on Unsplash
Abstraktioner gør kun transparens viktigere - brugerne skal kunne inspicere hvorfor resultatet er hvad det er - det skaber tillid og forståelse.
Analytikerne bør være involveret i udvikling og vedligehold af dit Data Client Library - jeg har tidligere skrevet om fordelene ved dogfooding .
Et Data Client Library er kun en formalisering af hvad mange i BI allerede gør - de har en folder med deres tidligere SQLer de har lavet for at løse andre problemer. Find den SQL der ligner mest, og lav de ændringer der skal til for at løse det nuværende problem.
Forskellen er at nu har vi mulighed for at samle den viden i et fælles bibliotek. Vi kan skrive unittest, vi kan lave versionkontrol, peer review, CI/CD og alle de andre moderne software praksiser der sørger for høj kvalitet i pipelinen.
Vi får versionering og traceability med på købet, da vi nu kan lave releases og logge hvilken version af koden generede et bestemt resultat.
Hvis man finder en fejl, eller DataWarehouse finder på en smartere måde at opbevare data på, så er det kun Data Client Library der skal opdateres - ikke hundredevis af enkeltanalyser, emails, Confluence sider og andre steder det kunne stå beskrevet
Centraliser din dataviden#
Det er ikke et nyt koncept at lave biblioteker til data - det er noget vi ser i API verdenen hele tiden. Det er nyt at tænke på den måde indenfor analytiker verdenen, hvor fremgangsmåden for ofte har været at det skal analytikeren “da selv vide”.
Everything-as-code skal selvfølgelig også gælde data - velkommen til den fagre, nye verden af kode!