Modelprocessen i Alm Brand
I sidste post beskrev vi, hvordan vi har bygget pipelines til at automatisere og standardisere vores Advanced Analytics modeller, samt deploye dem på vores container platform kaldes “Service Hotellet”. Hele Processen er illustreret nedenfor, hvor “prod” står for deployet i prod på Service Hotellet
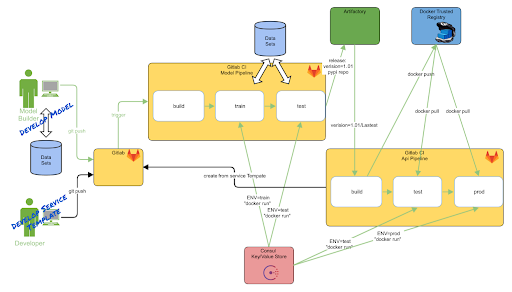
Denne post vil gå i yderligere detaljer om hvordan vi har struktureret vores værktøjer (venstre og midterste del af figuren) og hvilke fordele vi har fået ud af dette
Hvad vi opnår
Ved at gå fra batch scoring af modeller til APIer får vi en række fordele:
- Nem A/B testing
- Nem skalering - scor kun relevante kunder
- Portability - alle kan kalde en API
- Automatisk opgradering af modeller
En af de store gevinster ved en API er realtidsscoring af sine modeller. Realtid tænkes ofte som at være begrænset af DW opdateringsfrekvens, men vi indhenter også meget information i løbet af vores samtale med kunden som vi ikke har tilgang til i en batch verden.
Det giver en stor fordel til modellen, hvis vi f.eks. indhenter kundens adresse som vi ikke kendte - eller får at vide hvem de har forsikringer hos idag.
Modeludvikleren
Vores målsætning er at modeludvikleren skal kunne gå fra model til deployet API uden at skulle tænke over produktionsætningsdelen af processen. Vi har udvalgt og anvendt værktøjer der hjælper med at standardiserer interfaces og processer (docker, cookiecutter, gitlab-ci). Med disse standardiserede interfaces kan vi opbygge deployment processen omkring de antagelser og dermed bruge pipelines til at automatisere deploy processen.
Vi arbejder typisk i nogle steps:
- Opret nyt projekt
- Byg model
- Byg Python pakke
- Opret API
- Deploy
Opret nyt projekt#
Når vi starter en ny model, bruger vi cookiecutter til at generere en ny mappestruktur der indeholder alt boilerplate, som environment filer, pipeline konfiguration, Docker filer, git osv. Det giver os også en fælles forståelse når vi kigger gennem hinandens projekter - vi ved hvor rådata skal ligge, eller hvor koden der genererer visualiseringer er.
Byg model#
Vores modeludvikling foregår hovedsagelig i Pythons Scikit-Learn , et bundsolidt bibliotek der gør det nemt for os at prøve mange ting af. Modelbygningen er en iteration af eksplorativ analyse iJupyter Lab , et fantastisk værktøj til interaktiv kodning, hvorefter vi gradvist konverterer koden til at være en Python pakke. Alt dette hostes i Gitlab, så vi har styr på versionering og nemt kan arbejde sammen om at udforske nye features, nye modeller osv.
Byg Python pakke#
Når dele af koden begynder at ligge fast, bliver de lagt i en pakke, så vi kan udnytte traditionel software development tooling som automatiserede tests, coverage, git workflows og GitLab CI til kontinuerlig sikring at koden er stabil - en kæmpe fordel der gør det nemt for flere at genbruge kode og arbejde sammen på samme model. Her bruger vi vores interne PyPi server så vi nemt kan distribuere pakken, igen faciliteret af GitLab CI.
Produktionssætning#
Når modellen er klar til at produktionsættes, så bygger vi en Flask API rundt modellen. Der bruger vi igen cookiecutter til at oprette et nyt projekt der indeholder alt vi har brug for, som caching, logging, endpoint håndtering, dokumentation osv. Der udnytter vi igen GitLab CI, for at automatisere tests, oprette dokumentation, samt bygning af Docker image og deployment på ServiceHotellet - det eneste modeludvikleren skal tage stilling til er hvilken modelpakke på vores PyPi der skal bruges. I deploy processen hentes konfiguration fra Consul (distribueret Key/Value store), hvor man gemmer scalerings, loadbalancerings og datakilde konfigurationer.
Interne Værktøjer#
For at alt dette skal være gnidningsfrit, så kræver det standardisering af komponenterne. For at undgå “standardization by convention” hvor vi selv skal huske hvordan f.eks navngivning skal være, så har vi bygget et internt framework der definerer interface til modellerne. Frameworket er dog ikke kun til standardisering, det er også der vi samler al kode til genbrug - f.eks plotting kode eller Pipeline Transformers. Så ved vi at vores utility kode er gennemtestet og vi kan frigøre mental kapacitet til at fokusere på selve modellen. Denne form for “dogfooding”, hvor vi selv skriver de værktøj vi bruger i hverdagen, gør at vi hele tiden holder vores framework up-to-date med den måde vi arbejder bedst på.
Reflektioner og Fremtidige forbedringer#
Vi har med dette setup forsøgt at udnytte den praksis der har været bredt anvendt i den brede software udvikling i de sidste 10 år i forhold til pipeline styret udviklingsprocesser (gentagelige processer, time to market). Samtidigt har vi udnyttet den fleksibilitet vores Container Platform har givet os, i forhold til at få ny teknologi i produktion og dermed kan sikre os at der anvendes “the right tool for the job”.
Den primære forudsætning at dette lykkedes var at vi har baserer os på Open Source værktøjer. Service Hotellet er bygget til at kunne skaleres “usynligt” og “køre hvad som helst”, den største dræber for denne fleksibilitet er gamle enterprise licensmodeller, hvor der typisk regnes på antal cores eller (v)CPU’er.
En moderne container platform giver dynamisk service discovery og loadbalancering ud af æsken, og det giver nogle interessante fordele set ud fra et model perspektiv.
Med det setup der findes på Service Hotellet i dag kan vi skalere og opgradere til nye modeller uden nedetid.
Den næste tid kommer til at kigge på hvordan vi kan udnytte de andre muligheder der ligger lige for, så som: automatisk skifte mellem modeller baseret på performance, live A/B testing mellem modeller, Replikere indgående “live” trafik til test af modeller.
Vi forventer at vi med denne Analytics Platform kan levere nye og præcise anbefalinger, så vi ikke generer vores kunder med unødig information.